Building production grade LLM apps over your data
Mon, Aug 21, 2023
Read in 2 minutes
Tweet from @jerrryliu0. RAG is Retrieval-Augmented-Generation
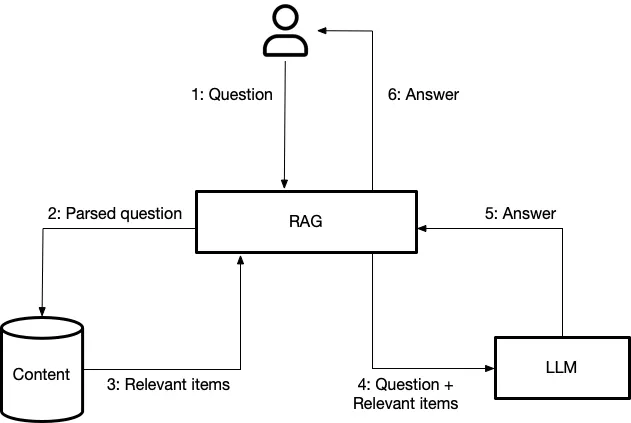
Compilation for the lecture from Llama-index found on youtube here
Here are 8 key considerations for building production-grade LLM apps over your data (RAG) 💡 (see 🧵):
1️⃣ Chunks used for retrieval shouldn’t necessarily be the same as chunks used for LLM synthesis ( @md_rumpf )
2️⃣ Embeddings should live in a different latent space than what you get from raw text, which can contain filler that biases the embeddings. Consider passing a transformed text representation or finetuning. ( @md_rumpf )
3️⃣ If retrieval isn’t returning the right context, you may need to dynamically load/update the data itself ( @md_rumpf , @bobvanluijt )
4️⃣ Design your pipeline for scalability. Latency times in prototyping do not translate to production workloads. Start with easy-to-use, high latency modules but aggressively try to shrink latency component by component ( @bobvanluijt )
5️⃣ Store data in a hierarchical fashion: summaries of documents and chunks for each document ( @bobvanluijt )
6️⃣ Robust data pipelines in prod don’t matter as much if you only load the data once. But they are especially important when the source data is constantly changing ( @tuanacelik , @md_rumpf )
7️⃣ RAG isn’t just question-answering: for summaries, you may need ALL chunks, for question-answering, you may need specific chunks. Your chunk sizes may differ depending on the use case ( @tuanacelik )
8️⃣ Embedding-based retrieval does not work well for entity lookup. Hybrid search combines benefits of keyword lookup with additional context ( @tuanacelik )